
Status Report: SEC disclosure text mining project
This is a brief note updating what I wrote earlier regarding mining SEC disclosures for information security intelligence.
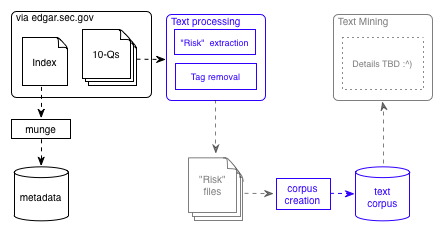
The diagram above shows my current progress and intent, as far as the technical bits go. Items in black are done. Those in red are being worked on, and those in grey have had no work done.
By way of quick summary, I took an SEC-created index (or indices, I forget) of documents available via FTP, munged it to obtain a list of 10-Qs, and downloaded the resulting 40,000 or so files. Since I trust the SECs file and directory naming conventions way more than any I could devise, I snarfed their index file(s) into a database, allowing me to link certain metadata about a given report - such as its filename on disk - to more interesting details, such as the name of the reporting firm, the report date, and so on. I considered snarfing the files themselves into the database, but the aggregate size makes this a non-starter. This is the stuff shown in black.
The blue “Text processing” box depicts the extraction of any risk factor disclosures made in the 10-Q, and the removal of XML tags, leaving only a file with risk factors identified by management. This task is made somewhat easier by the fact that the format of the 10-Q form is somewhat rigidly defined (but it’s still a PITA). For the purposes of this research, I plan to look at all narrative “risk factors” disclosures appearing in under Part II, Item 1a of the Form 10-Q.
Once these risk factors have been extracted and stored in what I have schematically shown as “Risk files”, the real fun can begin. Using the text mining capabilties of the R tm package, the disclosures previously isolated can be analysed in detail. One analytical dimension, of course, is simply whether “cyber risks” are called out, and if so, which ones, how often, and by whom. While the scare quotes above are used partially out of disdain for the cyber- prefix, more importantly for this work they are meant to suggest a certain fuzziness. I think I know a “cyber” risk when I see one, and many readers of this undoubtedly think the same. However, we want R to do the heavy lifting here, and that means coming up with a dictionary of “cyber risk” terms so that the risk factors appearing in the 10-Q specific risk files can be properly categorized.
Coming up with that risk dictionary will be the next task, and the next blog post.