
SEC disclosure text mining (minor) project update
I’ve been having fun dealing with the joys of unstructured text processing. The ambiguity in the previous sentence is deliberate: I mean both the joys of processing unstructured text, as well as the joy of unstructured processing of text. Of course, by “joy” I mean “frustration, punctuated by enough progress to keep me going while thoroughly reminding me I am not a competent programmer”.
Anyway, returning to the diagram of my little scheme (ooh, a schematic diagram!):
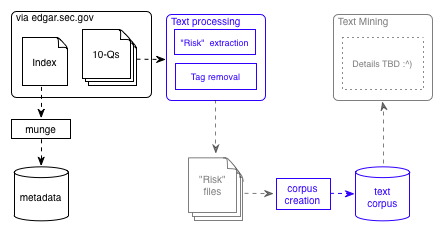
Since my last update, I have been focusing on the creation of the “risk files”. These are individual text files, containing one or more identified “risk factors” that a firm has identified in Part II, section 1A, of a quarterly report. My task is to identify which 10-Q reports contain this specific section, and to extract that section (and only that section) into a text file which can then be processed further. This is not as straightforward as one might think, because these reports are only semi-structured. Moreover, since they are so numerous, the mechanism must be automated. I am taking a trial and error approach. Essentially, I continue to refine the little Perl script I am using to identify 10-Qs with a “risk factors” section until its accuracy when run against groups of randomly selected input files is high enough. I should have an initial benchmark by this weekend. I expect it to be poor.
At any rate, once these files can be created with reasonable success, it will be desirable to determine which of them contain what I have been calling “cyber risks” (an abbreviated variant of the SEC’s “cybersecurity risks and cyber incidents”). To do this, I am taking baby steps toward creating an automated document classifier, which I will train with manually-identified cyber- and non-cyber risk files. I hope to report progress toward this classifier (as well as in the automatic extraction discussed in the previous paragraph) in an upcoming post.